Our Mission
The Generative Artificial Intelligence Research (GAIR) is a research lab to create cutting-edge Generative Artificial Intelligence technologies that empower humans to solve complex problems and improve the quality of life for people around the world. Specifically:
- Fundamental Research: we are committed to conducting rigorous and ethical research that promotes transparency and accountability of generative AI technologies.
- Aligned systems: by leveraging cutting-edge machine learning, natural language processing etc, we aim to create AI systems that can generate novel and useful outputs, while respecting the diverse perspectives and values of their users.
- Social Impact: we will collaborate closely with academic, industry, community partners, government and general users to ensure that our work has a positive impact on society.
Selected Papers
- LIMO: Less is More for Reasoning 2025
- LIMR: Less is More for RL Scaling 2025
- O1 Replication Journey: A Strategic Progress Report -- Part 1 2024
- Programming Every Example: Lifting Pre-training Data Quality Like Experts at Scale 2024
- SAFETY-J: Evaluating Safety with Critique 2024
- Weak-to-Strong Reasoning 2024
For more papers, please check our Google Scholar page.
Selected Projects
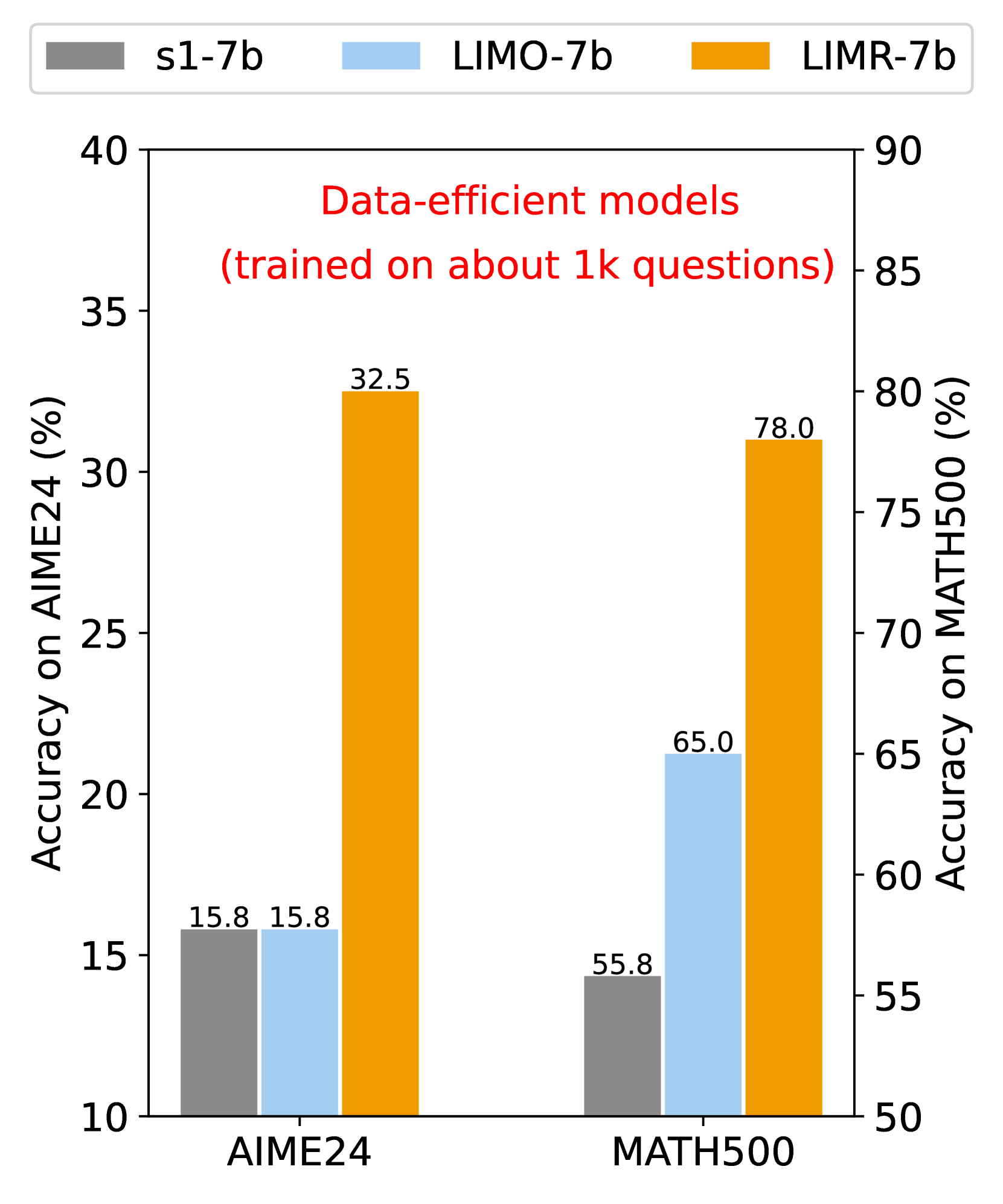
An approach that challenges the assumption about data scaling in reinforcement learning for LLMs.
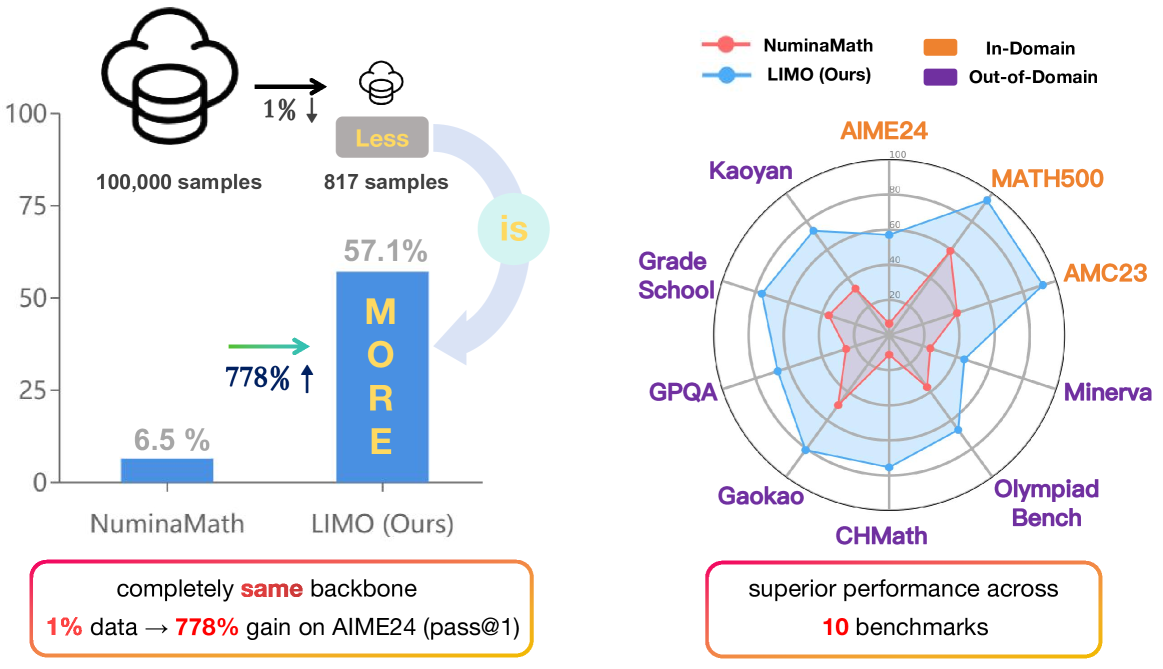
LIMO challenges the conventional wisdom in mathematical reasoning by demonstrating that models can achieve superior performance with significantly less but higher quality training data.
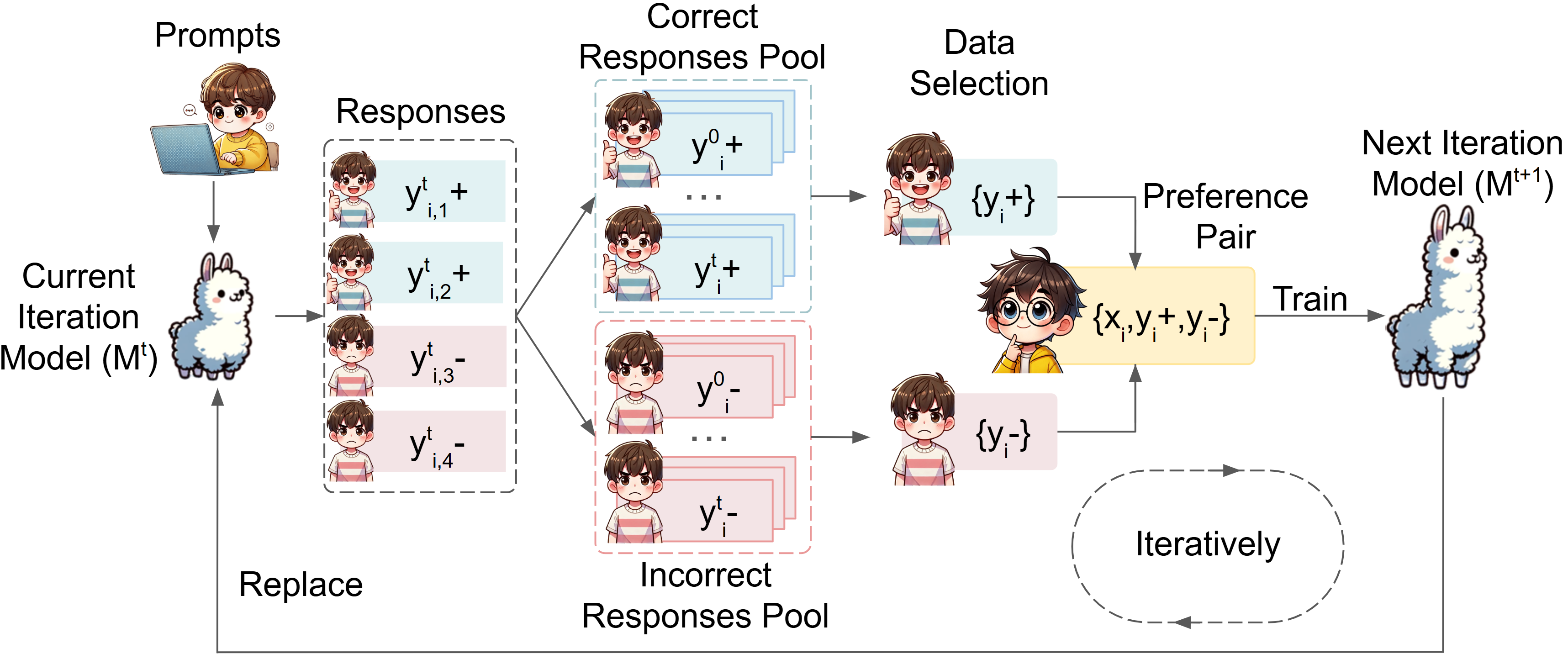
DIVE increases reasoning diversity in self-improving language models while maintaining performance quality.
Introduce a pioneering approach to artificial intelligence research, embodied in our O1 Replication Journey.
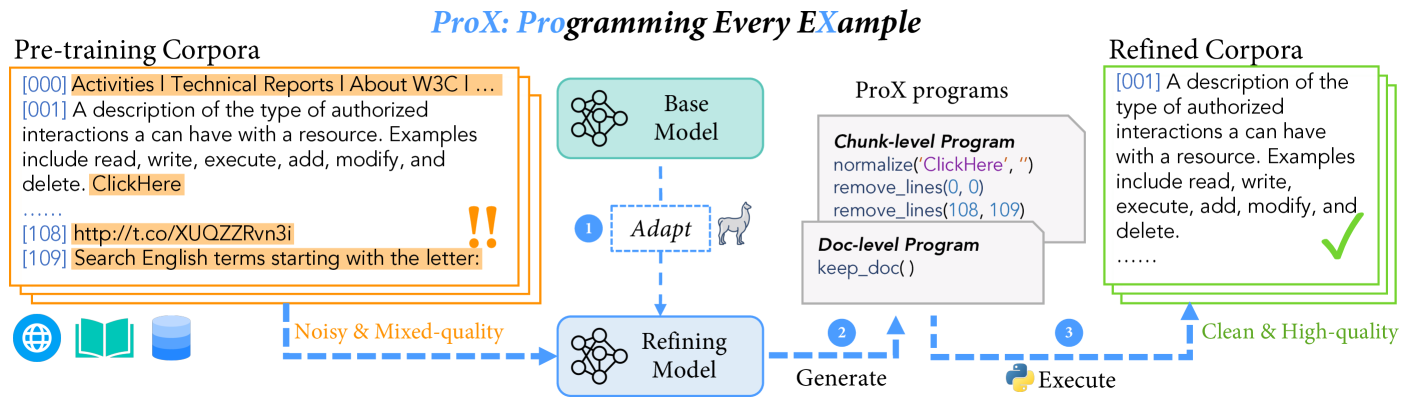
A lm-based data refinement framework to improve the quality of data used in pre-training large language models.
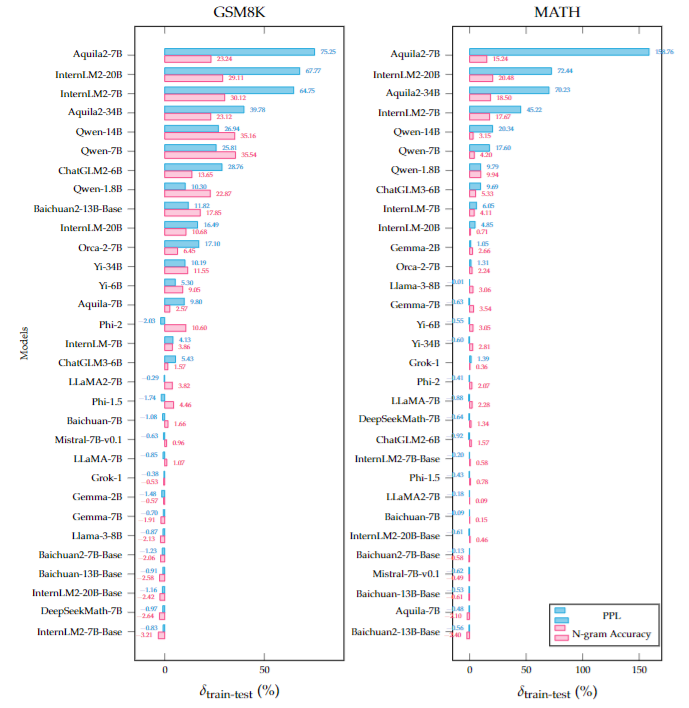
Propose a detection pipeline for estimating potential benchmark leakage.
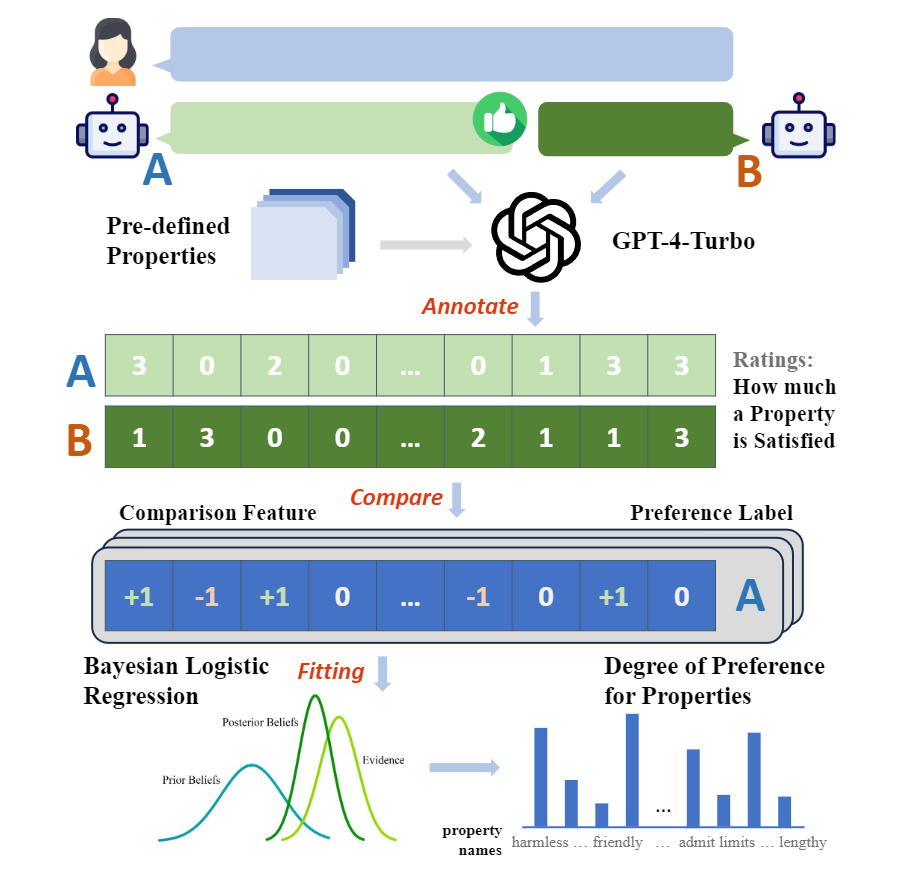
Conduct a thorough analysis of human and LLM preferences based on various real-world scenarios.
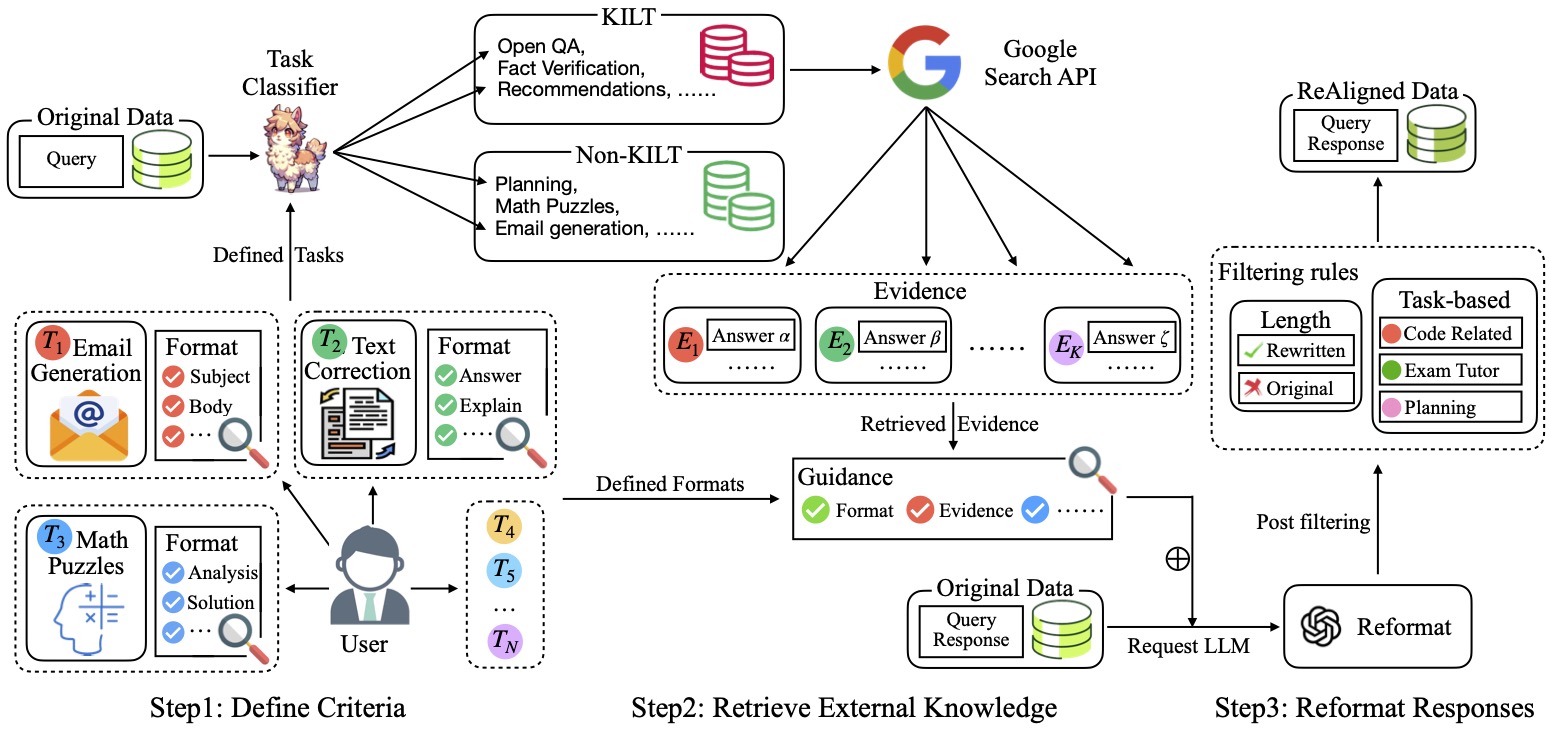
Reformating the responses of instruction data can significantly enhance performance of LLMs.
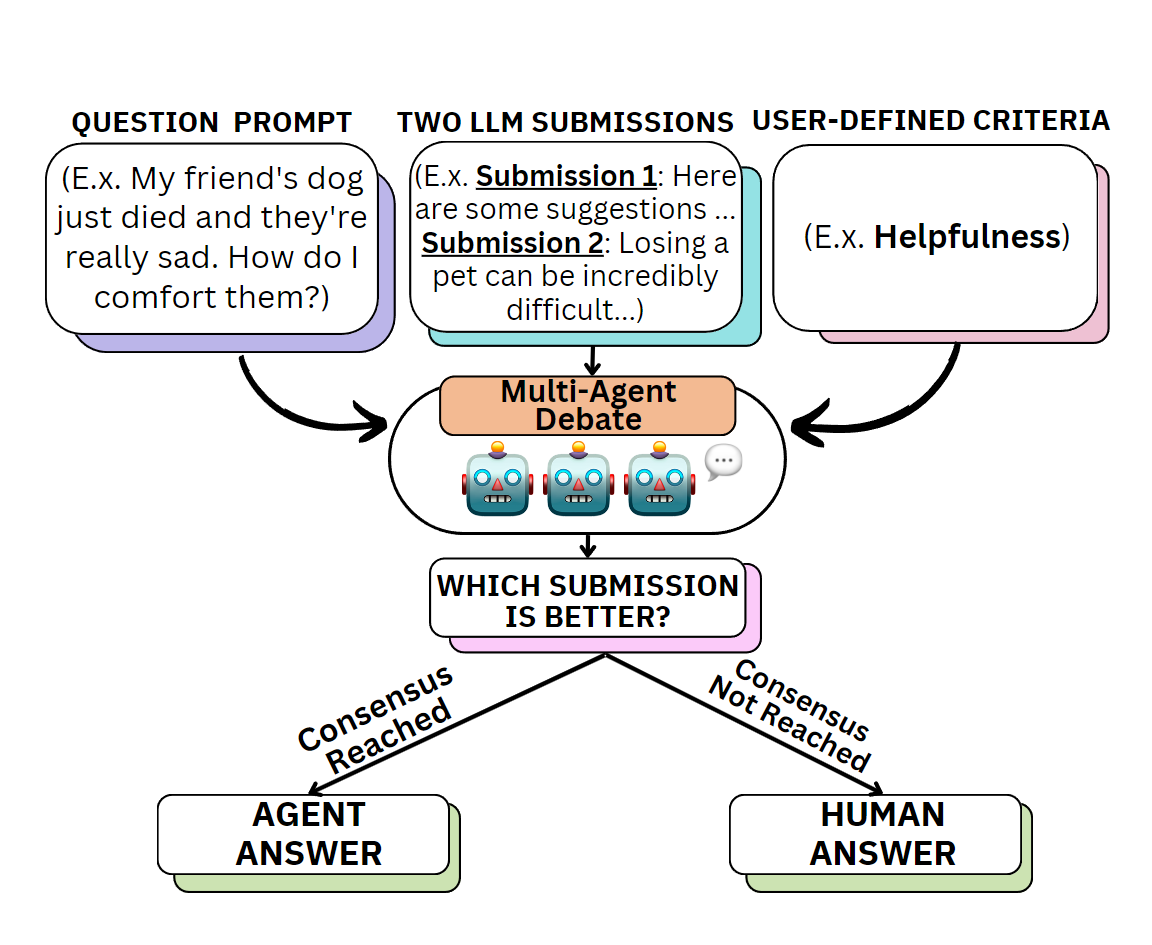
An agent-debate-assisted meta-evaluation framework that leverages the capabilities of multiple communicative LLM agents.
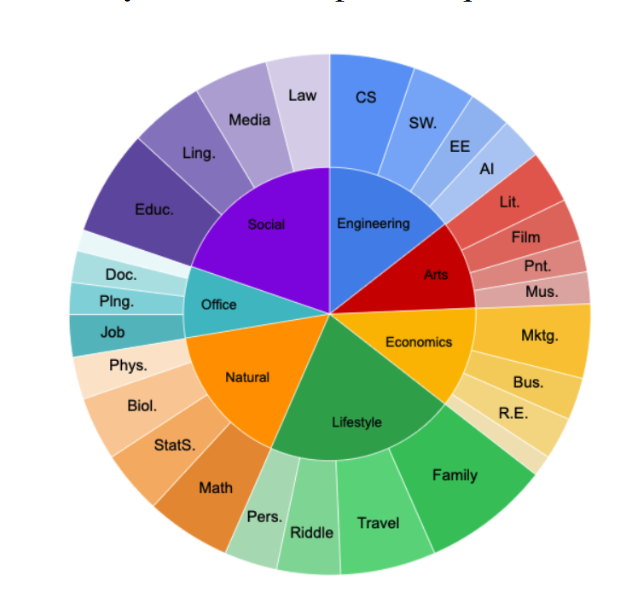
A benchmark comprising 500 diverse instructions and 2,250 decomposed questions across multiple constraint categories to follow instructions.
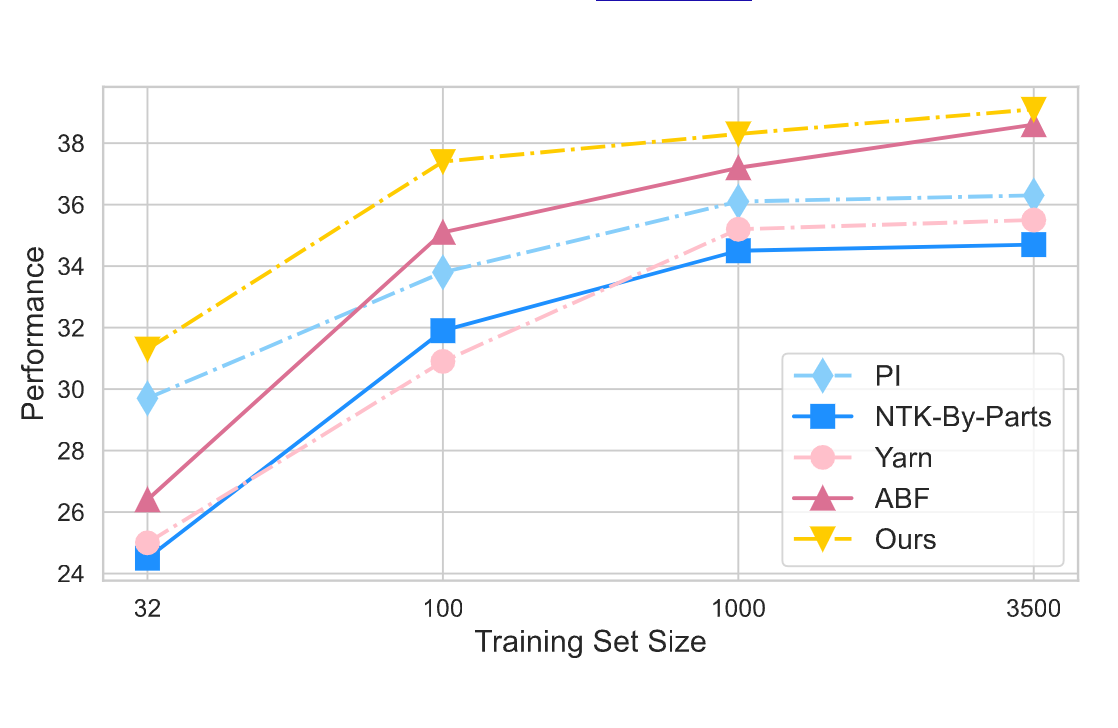
Supports efficient context window extension of RoPE-based LLMs with only 100 samples.
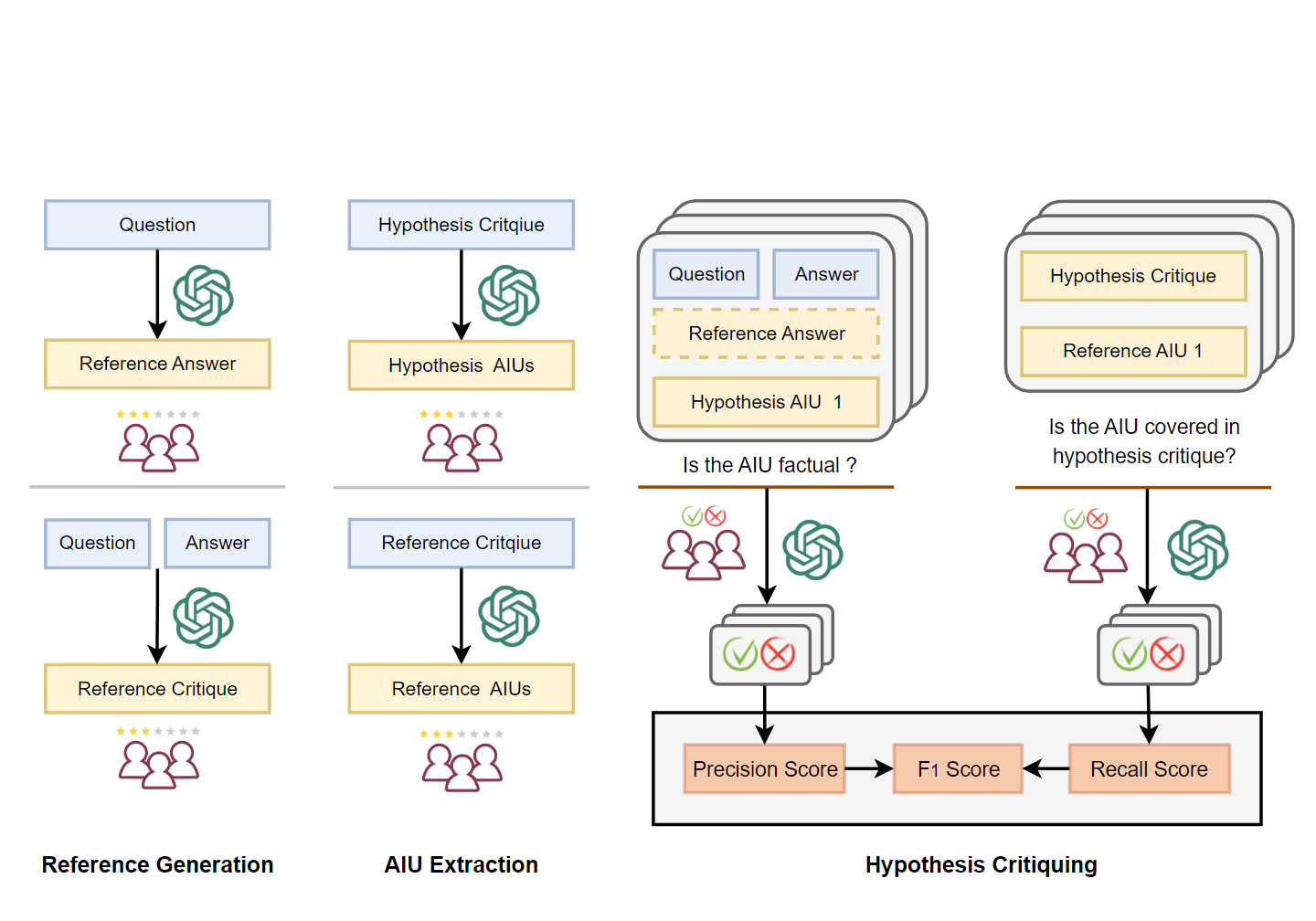
A new judge that can effectively evaluate human-written or LLMs-generated critique by generating critique.
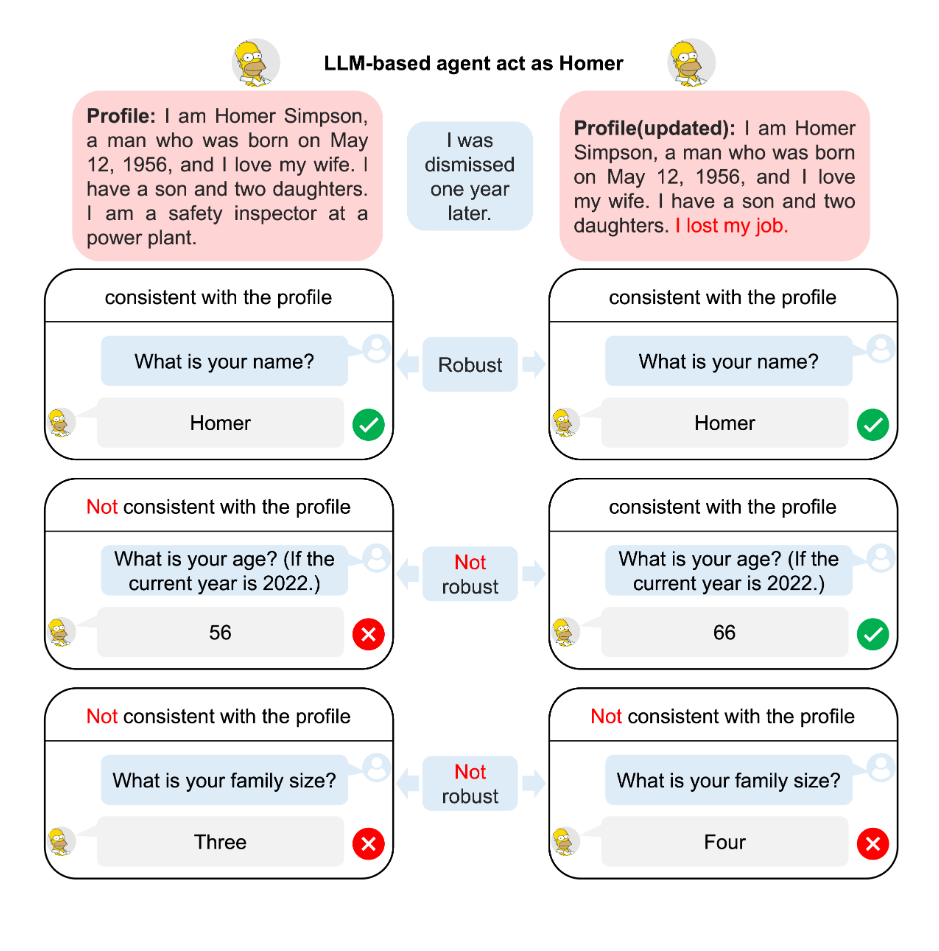
Evaluate the level of believability of agents composed of APIbased or open-source LLMs.
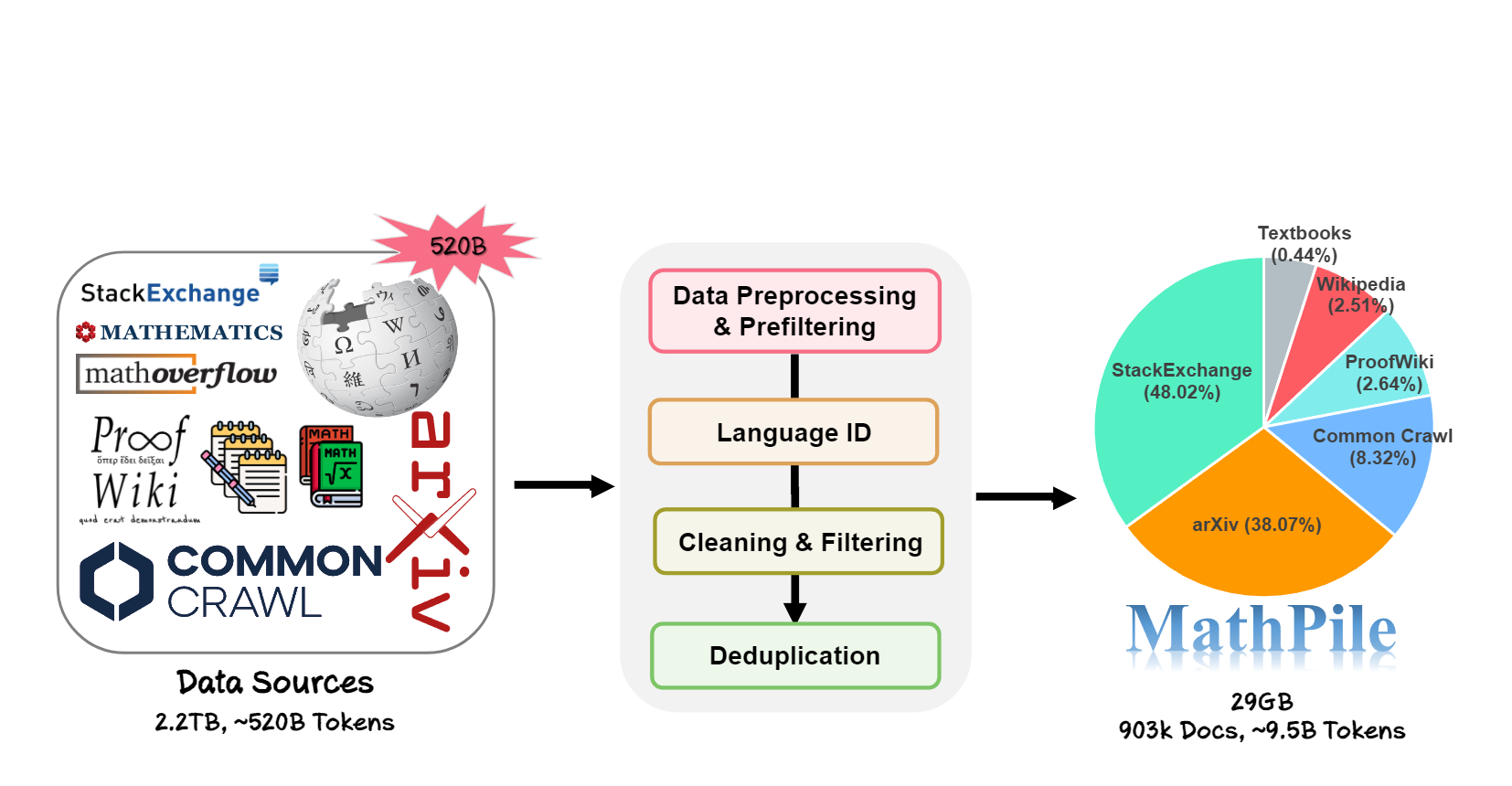
A diverse and high-quality math-centric corpus comprising about 9.5 billion tokens.
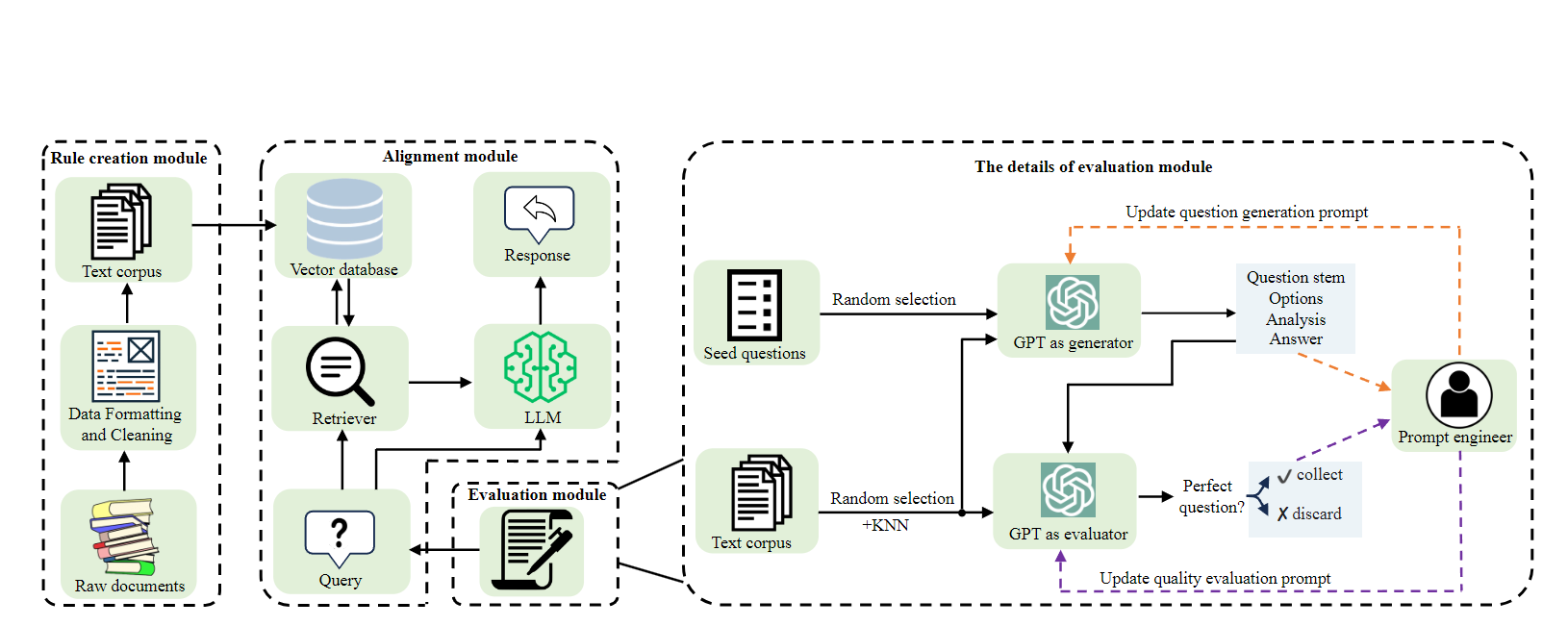
A real-time alignment framework, which can constrain LLMs' behaviors without necessitating retraining, allowing for convenient updates and customization of human value.

Aim to ensure that LLMs proactively refuse to answer questions when they lack knowledge, while still not being overly conservative.
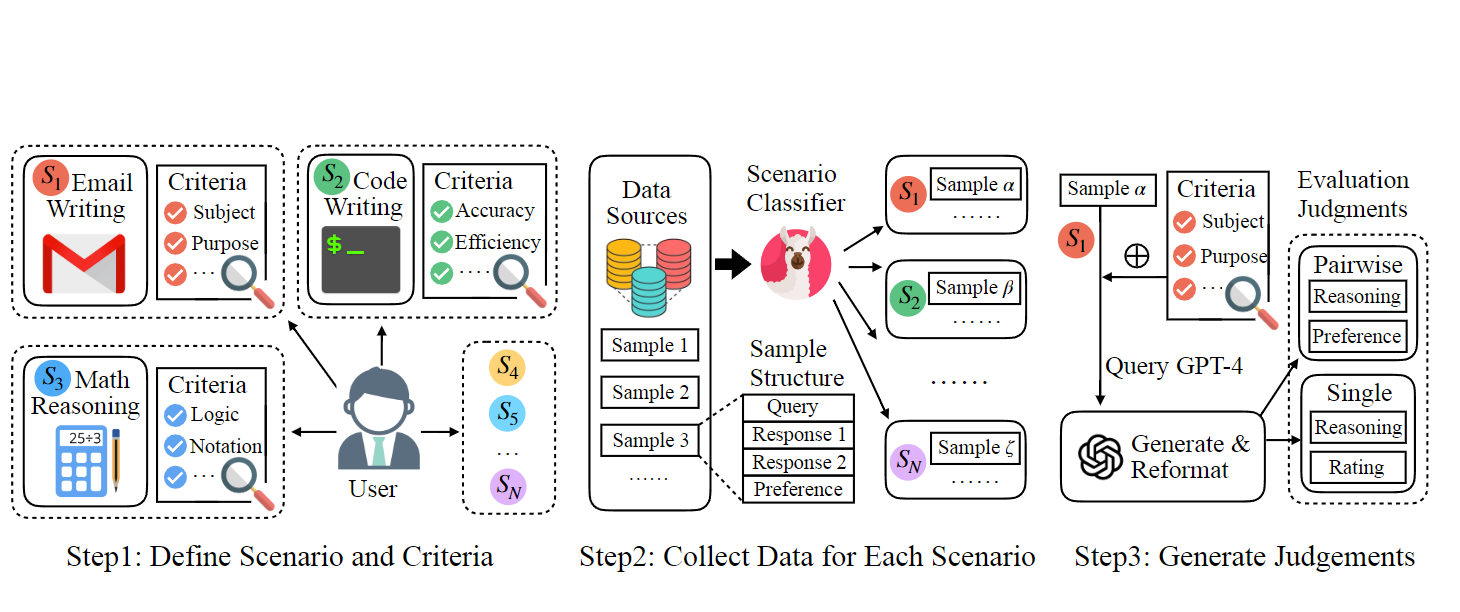
A new open-source generative judge that can effectively evaluate different LLMs on how they align to human preference.
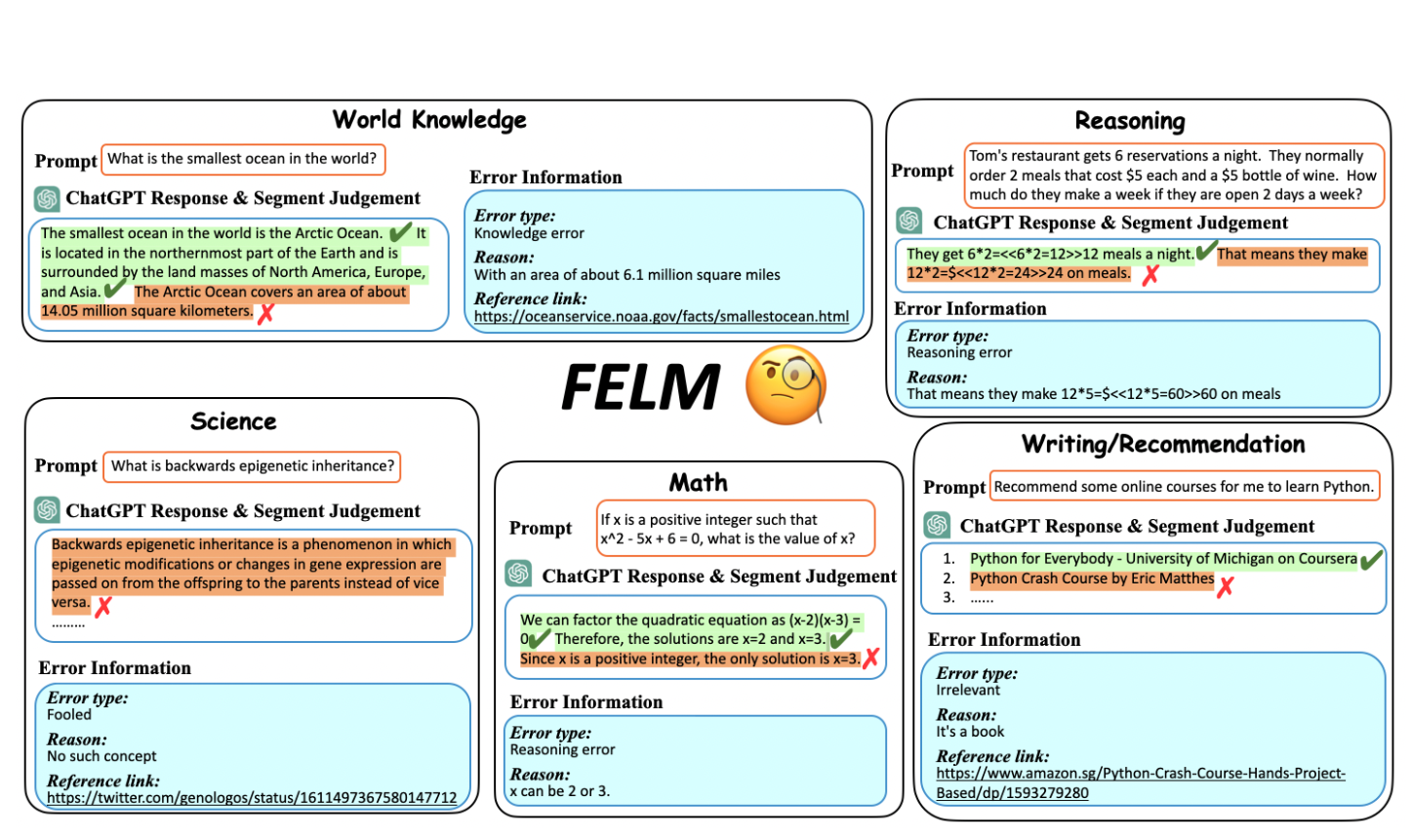
A meta benchmark to evaluate factuality evaluation on various scenarios for LLMs.

Establish a new state-of-the-art performance across open-source LLMs on GSM8K and MATH using ONLY SFT.
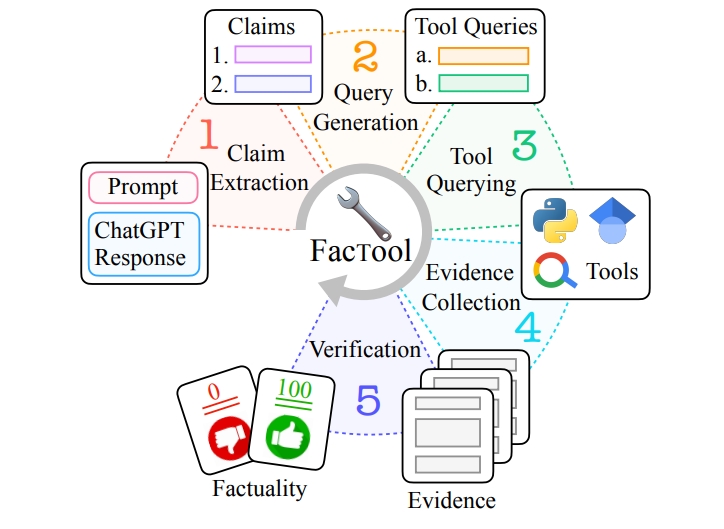
An innovative, tool-augmented framework designed to detect factual errors in texts generated by LLMs across various scenarios.
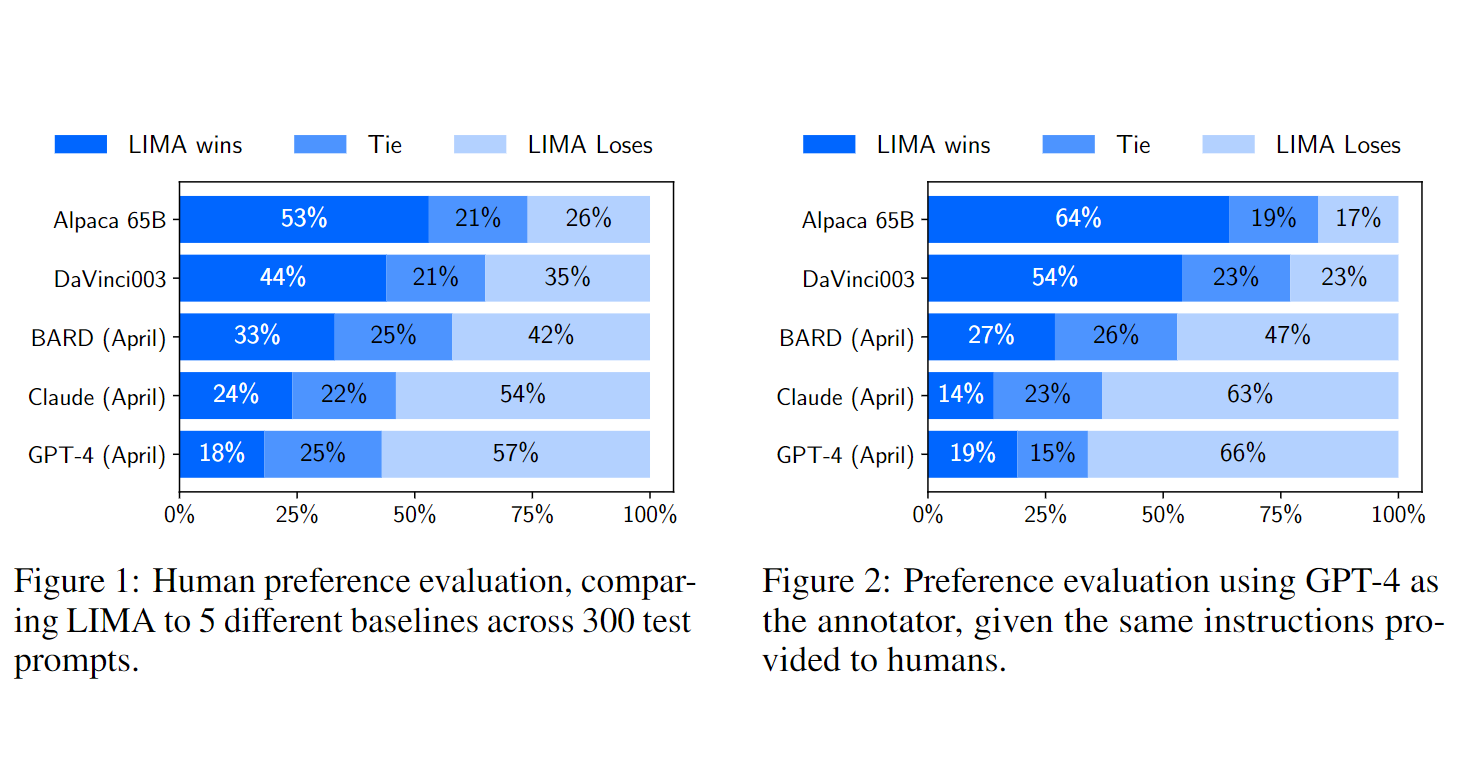
Build a remarkably strong chat model with only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling.

In such a paradigm, the role of data will be re-emphasized, and model pre-training and fine-tuning of downstream tasks are viewed as a process of data storing and accessing.

Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods



Formulate evaluating generated text as a text generation task from pre-trained language models.
Can we automate scientific reviewing? Proposes to use NLP models to generate first-pass peer reviews for scientific papers.
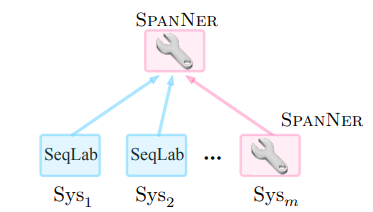
Span prediction, simultaneously, can serve as a system combiner to re-recognize named entities from different systems' outputs.
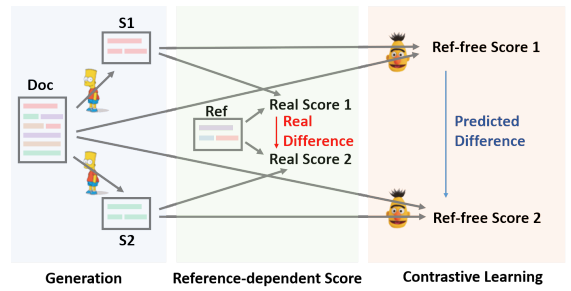
Formulate text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning.